How to use ChatGPT to web scrape EASILY

Hi, I'm Adam! I'm a high school student who loves programming. I have been learning programming for over 4 years. I started with Python, and then web development, specifically HTML, CSS, and JS, where I built many projects. I then learned Java. Now I am getting into machine learning, which is a whole new world that I am very excited about. I completed three programming courses, Colt Steele's Web Development Bootcamp, Modern Python 3 Bootcamp, and CS50 (Harvard's Introduction to Computer Science), which I completed the summer before 9th grade. Studying alongside first year students at Harvard and successfully solving the same problem sets that they were all given, gave me the confidence to continue on this journey.
By now you have probably heard of ChatGPT, the natural language processing chatbot, as it's been taking the world by storm. But did you know that ChatGPT can web scrape for you?
Let's say I am trying to web scrape Reddit to get a list of the post names in the subreddit r/programming. I normally have to open up VS Code, start a new project, and remind myself how to use the BeautifulSoup and Requests libraries for web scraping. However, ChatGPT makes it easier than ever to web scrape from sites and save time. Read on for two techniques to web scrape with ChatGPT, the first one can be done fully in the browser, and the second option is more customizable.
Steps for Technique #1: In the browser
First, I'll go to a subreddit on Reddit's website. I am using the old layout because it is more accessible to web scrapers, but the content is the same.
Open up the dev tools and inspect tab by right-clicking on the page and then clicking on inspect (Keyboard shortcut: Ctrl + Shift + I on Chrome).
Then press the button below, which will allow you to hover over any element on the website and see the HTML for that element.
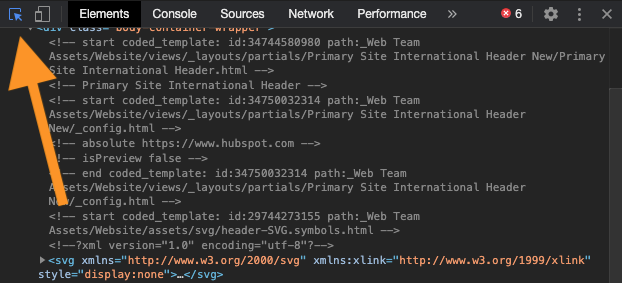
Then press on one of the titles, and it will highlight the HTML for that post's title.
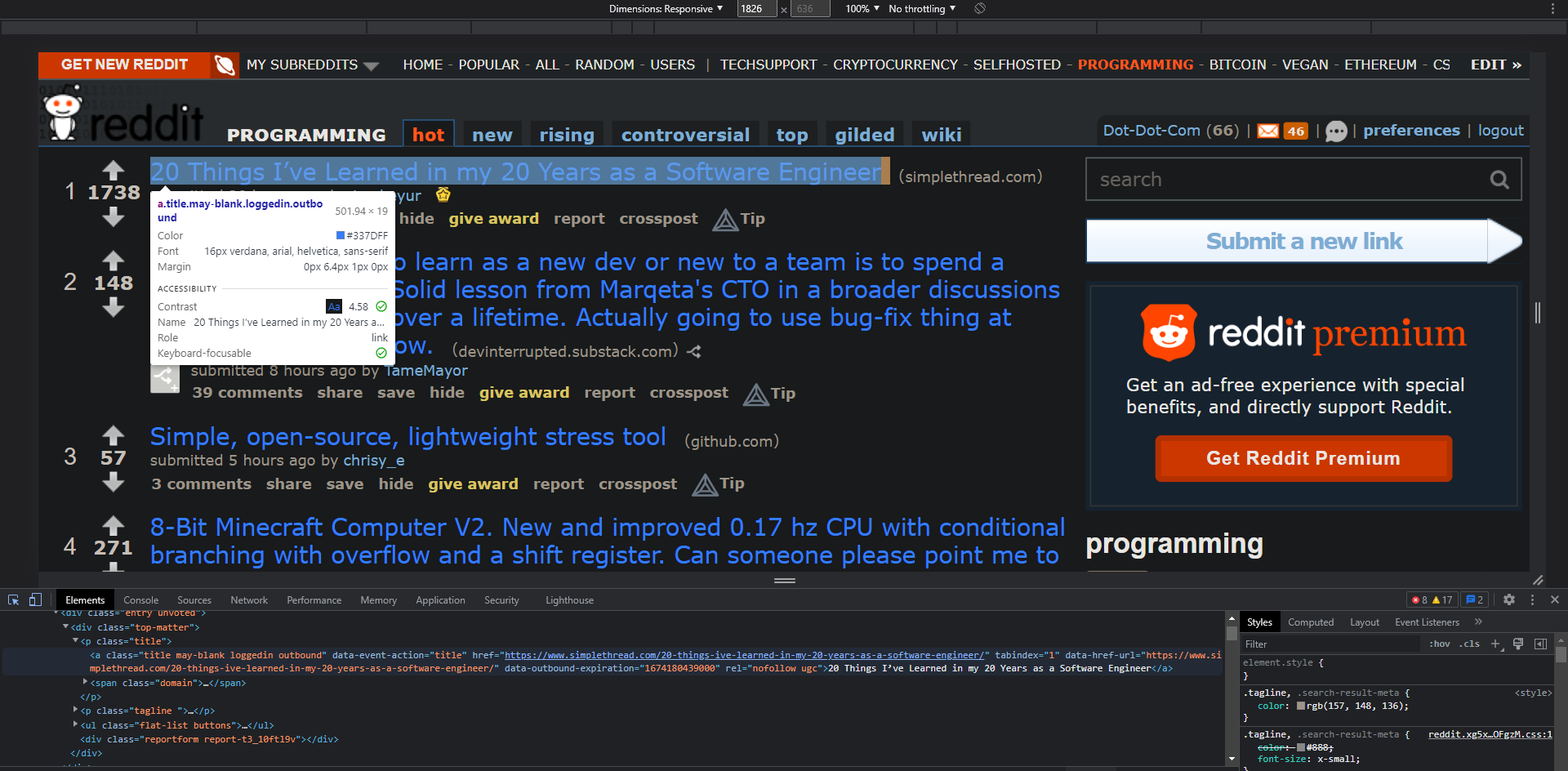

Then open up ChatGPT. Typing the text below will give you code that you can copy and paste into the console tab of the dev tools. Feel free to change the tag type and class name based on what you are trying to scrape.
I want to extract posts from a website. The posts are in an <a> tag with the class names "title may-blank". Give me JS code that will extract the first 25 posts and put it in an excel file. I want to run this code in the browser console.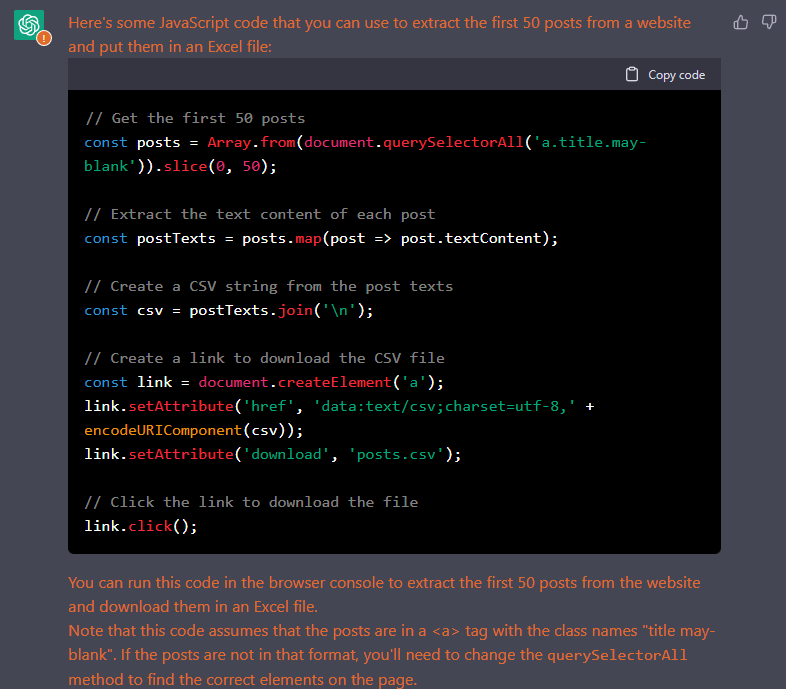
After a few seconds, the list of the Reddit titles downloads to your computer!
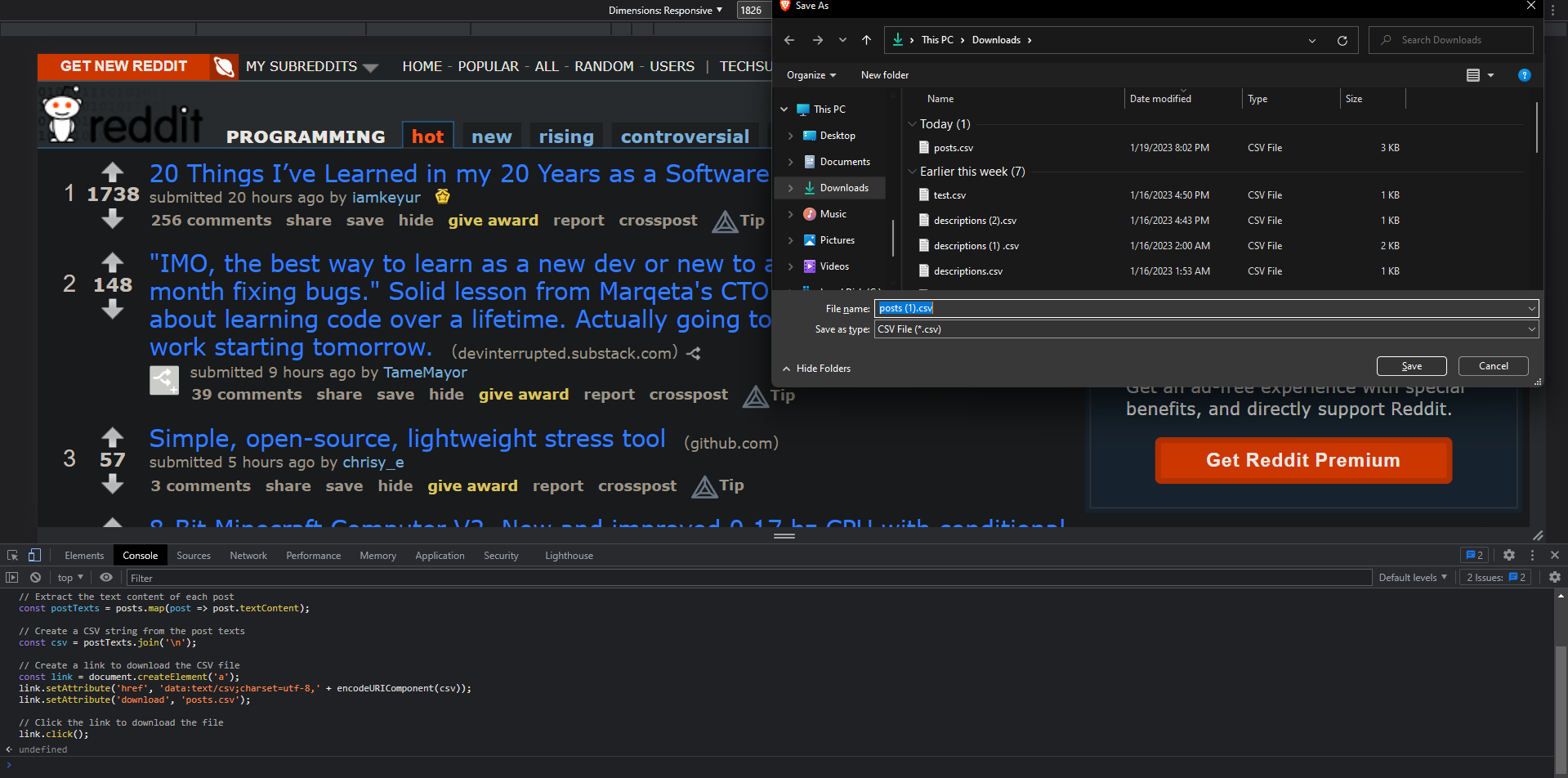
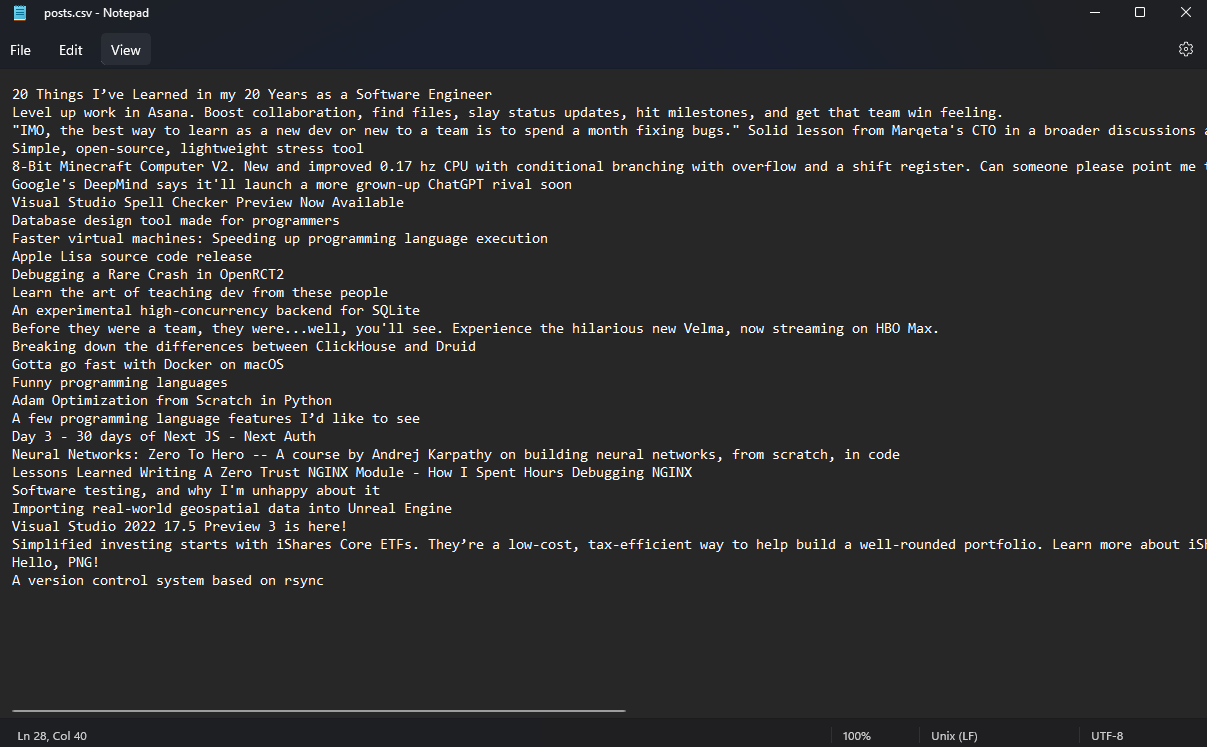
This technique is possible without leaving the browser and works great for beginner projects, but is relatively limited when it comes to web scraping. However, ChatGPT can also web scrape with popular libraries like BeautifulSoup, you just have to ask. This is a little more complicated, but much more customizable.
Steps for Technique #2: Python and BeautifulSoup
If you type this in ChatGPT, it will give you Python code:
web scrape data fromhttps://old.reddit.com/r/programming/using python and beautifulsoup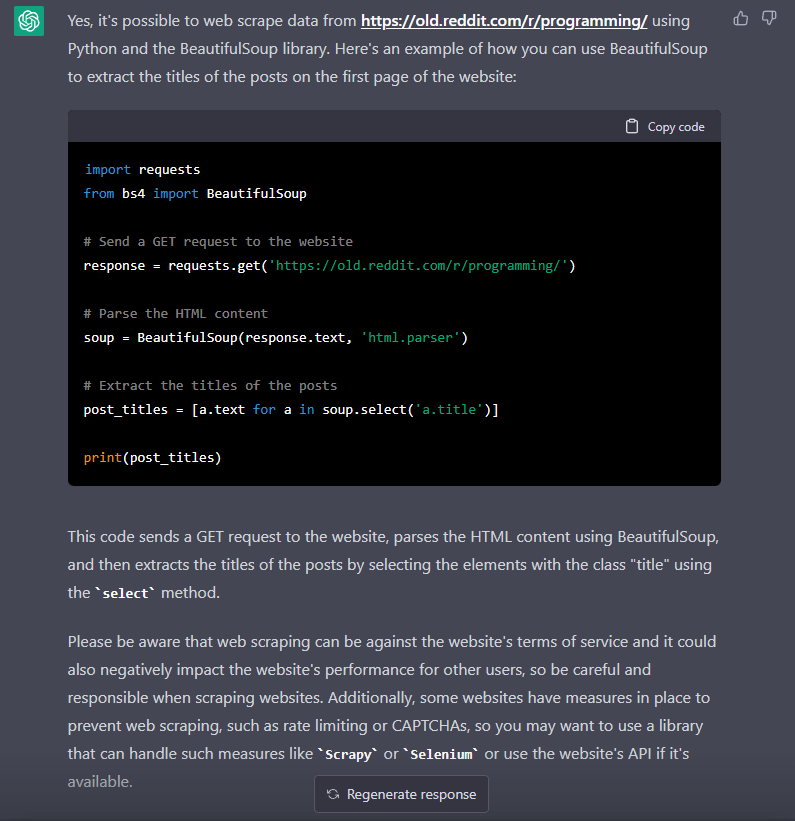
Open up an IDE or code editor (I use VS Code), make a new Python file and paste the code in.
Sometimes Reddit blocks the request if you try too many requests, so it is a good practice to add your user agent to the headers of the request. User agents help website servers identify where your request is coming from, which makes it less likely to get blocked. Luckily, ChatGPT can help with this too!
Asking ChatGPT to add user agents to this beautifulsoup and python code returns the code with this as an update:
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'}requests.get("https://old.reddit.com/r/programming/", headers=headers)Run the full code, and in the terminal, you see the scraped information!
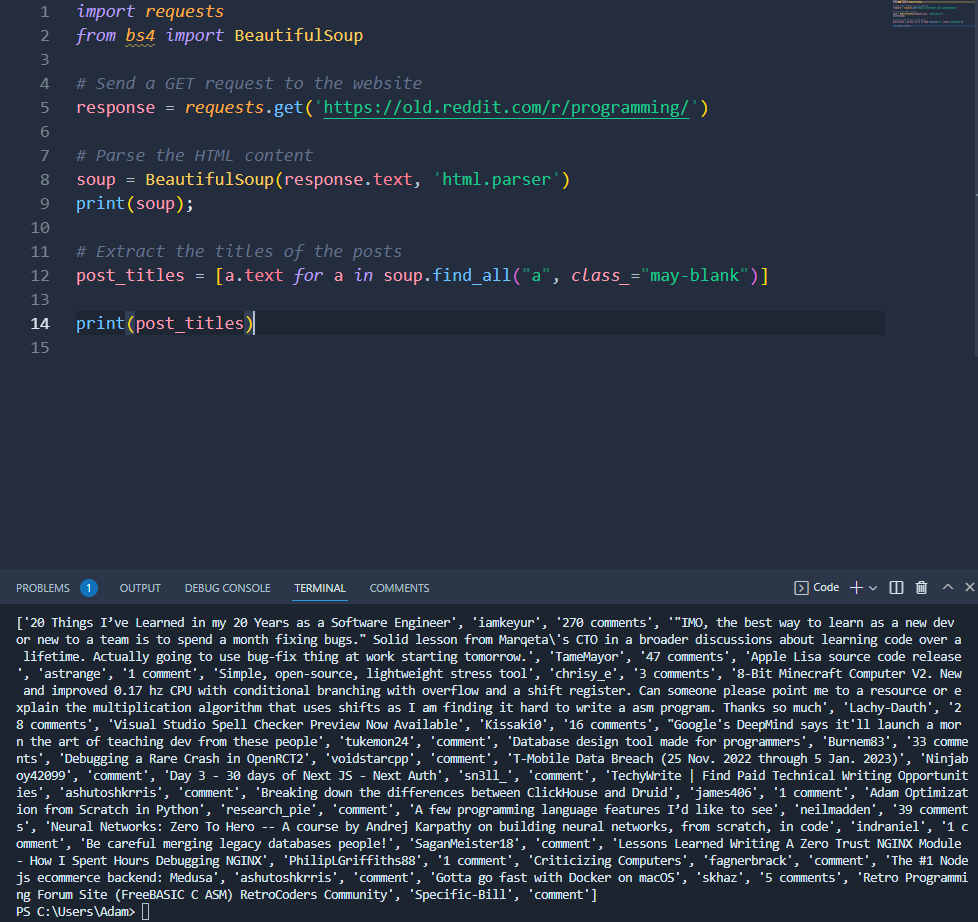
One thing you might notice is that the code scrapes the title names, in addition to the user who posted it and the number of comments it has. To get only the titles, you can ask ChatGPT this:
web scrape only the post titles fromhttps://old.reddit.com/r/programming/using python and beautifulsoupNow, to save it to a CSV file, just ask ChatGPT to
update this code to save the title names in a csv file after running.Quick note, make sure to change the folder that you are in inside of your terminal, because that is where the CSV file will be created. To do this, use the cd command.
After pasting the new code in, a CSV file will be added to your folder, and it contains all the article names!
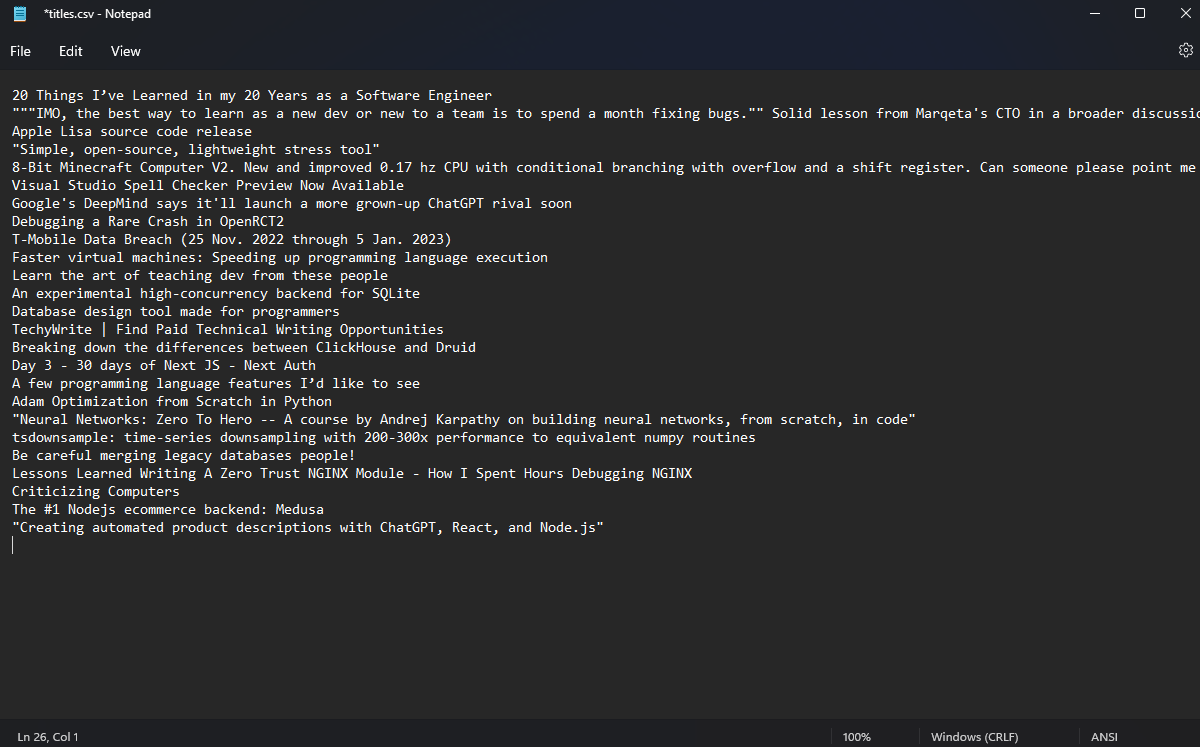
Final Code
Here is the final code:
import requests
from bs4 import BeautifulSoup
import csv
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
# Make a request to the website
response = requests.get("https://old.reddit.com/r/programming/", headers=headers)
# Parse the HTML content
soup = BeautifulSoup(response.content, "html.parser")
# Find all the elements with the class "title"
post_titles = soup.find_all("a", class_="title")
# Extract the text from the elements
titles = [title.get_text() for title in post_titles]
# Save the titles in a CSV file
with open('titles.csv', mode='w') as csv_file:
fieldnames = ['title']
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writeheader()
for title in titles:
writer.writerow({'title': title})
print("Titles saved in titles.csv file")
If you would like to add any more functionality, all you have to do is just ask ChatGPT using these same steps.
Conclusion
These techniques are super powerful and can save you a lot of time when scraping websites. A few years ago, I coded a web scraping project that took me hours and hours to finish, but if I tried to redo it now, it would take drastically less time because of ChatGPT.
Comment below what you think about coding with ChatGPT!




